Back in October, Google DeepMind's program AlphaGo defeated Fan Hui, a 2 dan professional, 5-0 in a 5 game match of go. This was a huge leap over the previous state of the art computer programs, which were generally hovering around a 5 or 6 dan amateur level. Over the last week, AlphaGo played another 5 game match, this time against Lee Sedol, who was the dominant go player over the last decade, and still one of the best despite having fallen out of the top spot.
I followed these matches and they caused me to reevaluate so many thoughts over the course of the past week that it feels like it would be insane to not write them down. As a 3 kyu go player, much of the considerations in the games are beyond my own comprehension, but the matches were commentated in multiple languages by top level players. English commentators included Michael Redmond 9p, Myungwan Kim 9p, and Cho Hyeyeon 9p. Their commentary helped me understand the games to a much greater extent than I would've gotten on my own.
I will mention some specifics of the game throughout this post. Keep in mind that as I am a relatively weak player (especially compared to the players in the game!) some of the things I say may be wrong.
Predictions before the match
Predictions of who would win the match seemed to be split neatly by whether the predictor was more familiar with machine learning or with go. Go players were extremely confident on Lee Sedol (expecting a 4-1 or 5-0 victory) and software engineers who did not have much experience with the game were mostly confident on AlphaGo. Meanwhile, DeepMind believed the match to be about even, and I was personally expecting Lee Sedol to win (about 70-30), but as the match neared I realized that AlphaGo had more advantages than I thought and so my expectation of the odds approached even (though I still slightly favored Lee Sedol).
It's interesting to think about why this split occurred. I think that the various people making predictions were missing a lot of information, some of which was possible to know, some not.
The skill gap between Lee Sedol and Fan Hui is huge.
The media described Fan Hui as a "Go Champion" which, while technically true, probably misled a lot of people to believe that he is near the top of professional players. There's no official worldwide rating of go players (the professional dan level is really a measure of past accomplishments, not of current skill), but goratings.org maintains an unofficial one, and at the time of writing suggests a gap of more than 500 Elo between the two human players.
To put that in perspective, if Lee Sedol and Fan Hui were to play, everyone would expect a 5-0 result in favor of Lee Sedol. Moreover, there could easily be a professional player who would be expected to go 5-0 against Fan Hui and also expected to go 0-5 against Lee Sedol. I think that people who don't have much experience with the game severely underestimated how big this gap was.
Fan Hui won two of the informal games against AlphaGo in October.
This fact should have been widely known, and was very clearly mentioned in DeepMind's paper about AlphaGo. The full games list is in Extended Data Table 1. And yet, because most people only got their news from the media and did not read the original source, this fact was mostly missing.
The formal games were played with 1 hour of main time and 3x30 seconds byoyomi, while the informal games were played with no main time and 3x30 seconds byoyomi. Though the formal match was 5-0 in favor of AlphaGo, the informal games were only 3-2 in favor of AlphaGo.
Go professionals were fairly confident about saying that the play of AlphaGo in those games was about the level of a middle-tier professional. Even if you know nothing about go, the results of the informal matches should tell you that assessment is about right.
DeepMind could have changed the amount of computation power between matches.
One thing I learned during the matches is that Monte Carlo Tree Search (the main technique behind modern go playing programs) generally gains strength logarithmically in the amount of computing power. One figure I've heard is that the program gains about 60 Elo for every doubling of computing power. If we assume that AlphaGo was about 150 Elo stronger than Fan Hui, then to cover another 400 Elo would only require about 7 doublings of computing power, even with no algorithmic improvements.
Now maybe you think that it would be unreasonable for DeepMind to use 125,000 CPUs and 25,000 GPUs, and you might be right. However, without knowing how much computing power AlphaGo would be using, there's no way to know how much strength needs to come from algorithmic improvements or improvements from reinforcement learning. As it turns out, DeepMind did use more power during the match with Lee Sedol, but only about a factor of 1.5.
Additionally, the time controls were roughly doubled from the match against Fan Hui. Instead of 1 hour + 3x30 seconds byoyomi, the matches were played with 2 hours + 3x60 seconds byoyomi. Exactly what effect this has on the game is unclear, but from the Fan Hui matches, longer time controls may favor AlphaGo.
How much does reinforcement learning help?
This is the fact that nobody could have known, because it was exactly this question that the match was set up to answer. DeepMind certainly had some estimates, but with reinforcement learning there is a risk that your entire population misses some key features of the problem space, potentially ones that are easily (or not-so-easily) exploitable.
Monte Carlo Tree Search
AlphaGo, just like the programs that preceded it, is mostly based on Monte Carlo Tree Search (MCTS for short). The rough idea is that exhaustively searching the game tree, even with alpha-beta pruning, is going to be too much computation once you get past a few ply. By taking a random sample instead, you can search much deeper, or even to the end of the game, for a much smaller cost.
It turns out that in go, Monte Carlo Tree Search is quite effective. The usefulness of your current position against random moves turns out to be quite related to the usefulness of your current position about the best moves. However, it's not perfect, and the older bots had very noticeable weaknesses. I never personally played against any bots and only observed, so some of my observations might be a bit off.
Overvaluing the center
This was by far the most noticeable difference between bots and human players. So much so that you could often spot a bot by its first move. I believe the reason for overvaluing the center is the fact that while the center can be reduced effectively, attempting to do so with random moves will be unsuccessful, and therefore the Monte Carlo Tree Search will believe that the center is more secure (and thus more valuable) than it actually is.
Difficulty with Semeai
Semeai is the Japanese word for a capturing race. This refers to a situation in which there are two opposing groups, neither of which can live without capturing the other. The one that will live is then the one that is able to capture the other one first. For a human, determining who wins a semeai is usually as straightforward as counting to see who has more liberties. Some situations allow one side to acquire more liberties, but those are the exception and not the rule.
However, for Monte Carlo Tree Search, in order for the program to know that one side's stones are dead, it needs to focus on the section of the game tree where both players repeatedly play in that area. Once you are past the most basic positions, it is likely that Monte Carlo Tree Search gets the result completely wrong.
Difficulty with Ko
The ko rule prevents a player from immediately repeating the previous board position. This matters when a player captures a single stone, and the stone they just played could be recaptured by their opponent. Because of the ko rule, their opponent must play another move elsewhere on the board, allowing the first player the option of whether to respond to the move or to "win the ko" by preventing recapture in some fashion.
Oftentimes, a position can be mostly settled, but with potential for the result to change significantly if one player can move locally twice in a row. In this case, neither player will want to play in that area in normal circumstances, but if a ko happens, then it can be used as a source of threats. This sort of circumstance can be difficult for Monte Carlo Tree Search, because a ko fight can last a very long time, the order of moves is particularly important, and the moves that might be played during a ko are different from the moves that you'd play otherwise.
AlphaGo's Play
AlphaGo's structure is still mostly based around Monte Carlo Tree Search, but with a neural network called the policy network suggesting likely moves, and a neural network called the value network that estimates the strength of a position, allowing for a more traditional finite-depth search instead of playing random moves to the end of the game. While watching AlphaGo, I was particularly interested in seeing whether AlphaGo had inherited any of these weaknesses from the older Monte Carlo Tree Search programs. After the match, I believe that the answer is decidedly yes.
Overvaluing the center
I'm too weak to point to any mistakes, but I did notice some patterns in game 4 and 5 that seemed telling. Here is the position from game 4 after move 68.

Notice that Lee Sedol, playing white has two solid corners in the bottom left and bottom right, along with two groups along the left and right sides of the board that are mostly alive. Conversely, black has two large walls in the middle of the board, with potential territory between them.
Similarly, here is the position from game 5 after move 68.
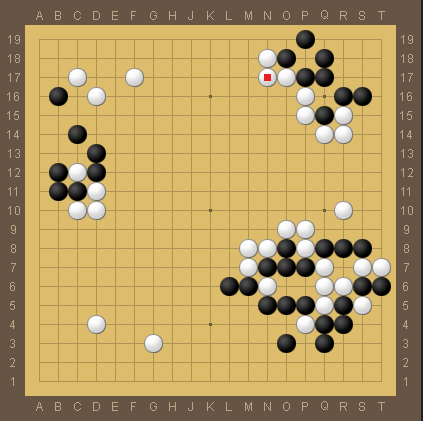
Lee Sedol, this time as black, has taken two corners (upper right and bottom right), and has a very stable group along the left side of the board. Meanwhile, white has some strong walls allowing for a lot of potential, and the game at this point depends on how much territory will come out of it.
Now, from my point of view the game could be considered balanced here. But it felt to me that Lee Sedol repeatedly tried to find joseki that would give him territory and his opponent influence. Given how well games 4 and 5 went, it seems that perhaps AlphaGo was overvaluing the influence it got from those openings, and giving away too much territory as a result.
Difficulty with Semeai
I think this was the clearest weakness in the entire series. In both games 4 and 5, AlphaGo played out sequences that did not work, and gave its opponent an advantage as a result.

This is a simplification of the sequence starting from after Lee Sedol played move 78 at L11. Moves 1 through 11 are played in the actual game, and we can see that if white follows black to the edge of the board that black has two liberties, while every white group around it has at least three. Since black has no way to gain additional liberties in this situation, black is dead.
It turns out that move 12 can actually be played at O8 and black is still dead, and this gives white more points than the simpler variation, so the actual game went in that direction. The existence of this sequence has led professionals to point to black's move 79 at K10 as a mistake. I believe that AlphaGo considered this sequence, quite possibly with the actual game as the main line, but had to stop before the local situation was completely finished, and misevaluated the black group as alive.
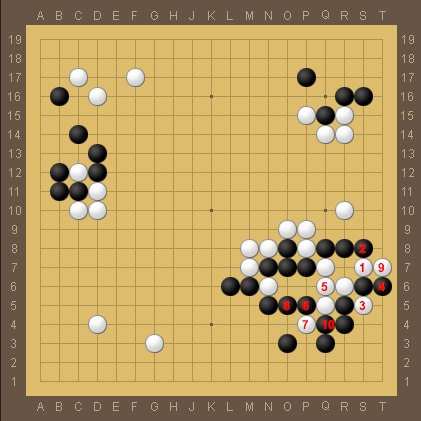
This is the actual sequence from game 5 starting with white's move 50 and ending with black's move 59. Here white's group ends up being captured first. The fact that AlphaGo played this sequence indicates that it thought that it was going to win the race against black's stones at Q8, R8, and S8. Demis Hassabis attributed this misread to not knowing a tesuji, which in this case starts with black's move 4.
It seems difficult to imagine that this is the case, since the shape is amazingly common. Moreover, AlphaGo continued to play in the area with moves 5 through 10. If the problem were really that AlphaGo didn't know about move 4, then it should have noticed its error as soon as that move is on the board. I believe that what actually happened is that because the capture sequence is quite long, until after move 10, AlphaGo was cutting its search before the capture happened, and misevaluated its stones as alive.
However, the capture sequence does involve a second (also very common) part of the tesuji where if white captures the stones at S6 and T6, black needs to play another stone at S6. It's possible that this was the move that AlphaGo overlooked, but again it seems unlikely to me.
Difficulty with Ko
Of the three weaknesses that I mentioned above, this is the one that is by far least supported by the series. AlphaGo never needed to play a serious ko. In game 3, Lee Sedol did create a ko at the end of the game, but AlphaGo was leading by so much at that point that it did not seem to be a great test.
However, several of AlphaGo's moves did seem to be ko-averse. It is possible that this behavior arose because of a weakness to ko, and rather than learning to deal with ko during the reinforcement learning, AlphaGo learned to avoid it.
The Horizon Effect
AlphaGo's play had other oddities that are harder to explain. One possible explanation is through the horizon effect, which can be found in chess playing programs. If a program is doing a fixed-ply search of the game tree, then that forms a "horizon" of how far the program can look ahead. The program can then trick itself by trying to push bad results past the horizon.
For example, imagine a chess program has a horizon of 18 moves and sees that in 18 moves it will lose a queen. However, it might also have an option to sacrifice a rook immediately, delaying the queen loss by a move. Because of the horizon effect, the program might think that it is only losing a rook on this line, and sacrifice the rook despite the sacrifice having no value.
Potentially bad exchanges

This diagram shows the sequence in game 1 starting with white's move 130 and ending with black's move 135. In human play, the exchange of move 1 for move 2 would be considered a mistake if white's plan was to play 3 rather than cut (play at 6). This is because the overal result of the exchange is that white's stones have one fewer liberty, potentially allowing black to have more possibilities in the corner.
Even if AlphaGo read through the entire corner sequence and found that the extra liberty doesn't net any additional points, it could give black additional ko threats, and the exchange of 1 for 2 is also a potential ko threat for white, so this exchange really seems to have no upside, and potential downsides.
I don't know for sure, but these sorts of exchanges could be due to a horizon effect. Perhaps making this sort of exchange delayed some sequence, and AlphaGo preferred the uncertain position to the one two moves later.
Meaningless moves

This is the position in game 5 after white's move 158. Playing this stone changes essentially nothing about the game. Black can immediately capture the stone that white just played. This move doesn't lose points, because black played an additional stone inside of his territory in order to capture, but it also doesn't accomplish anything except remove one of white's ko threats.
AlphaGo played many of these moves in game 5 (for example, moves 164, 178, and 184). Since these moves don't change the result of the game unless there's a ko, they are extremely minor mistakes, but they are certainly not good moves. When AlphaGo played such moves, it seemed like it was trying to delay playing the actual game, again, potentially because of a horizon effect.
In fact, in normal circumstances these moves are doubly bad, because they were played while Lee Sedol was in byoyomi, but AlphaGo was not. So every time AlphaGo played one of these moves, Lee Sedol effectively got an additional minute to think about the rest of the game.
Playing From Behind
One of the absolute strangest things about AlphaGo was the moves it made in game 4 after realizing that it fell behind.

This was the first of several bad moves that AlphaGo played. These moves were bad in the sense that Lee Sedol would need to make a huge oversight in order for them to gain any points, and in fact they lose points for nothing in return with proper responses.
When you think about how AlphaGo plays, this makes sense. AlphaGo is attributing some amount of chance that its opponent does not respond to one of its moves, and in those branches of the search tree, it sees that it will be ahead. However, by doing so, it ensured that it was even more behind. It seems that AlphaGo prefers known chances to unknown chances.
For a human player, when you're behind you try to keep the game close, taking the chance that your opponent makes a small mistake or oversight that allows you to jump over that small gap. AlphaGo, on the other hand, does not give much consideration to those unknown chances, and prefers to jump right into the existing positions on the board, even when the proper response results in the gap widening.
"Superhuman"
Some people have described AlphaGo as being superhuman at go. However, superhuman can have many possible meanings. Here is a simple "superhuman scale" that includes these meanings.
- Superhuman level 0 - Outperform 75% of current humans.
- Superhuman level 1 - Outperform all current humans.
- Superhuman level 2 - Outperform all current and future humans.
- Superhuman level 3 - Collaborating with a human does not improve performance.
In the case of AlphaGo, it is clear that it is past level 0 on this scale. I believe it is also clear that it is not yet at level 2. There will naturally be debate on whether it is at level 1. I believe it is not. My impression from games 4 and 5 is that if Lee Sedol were to continue playing AlphaGo in its current state (and ignoring possible issues with fatigue), that he would be favored when he has white, and close but slightly unfavored when he has black.
However, it seems likely that AlphaGo will be able to pass level 1 within a few years. Level 2 is probably several years out. Level 3 seems impossible without significant new breakthroughs in the field. For comparison, I would feel somewhat comfortable putting Stockfish at level 2.
AlphaGo's effect on go
More players
Without a doubt, the match between AlphaGo and Lee Sedol was a huge amount of publicity for the game. As far as I'm aware, it was the first widely watched go match that had live English commentary. I know that many people are starting to learn the game because of this match, and the American Go Association was also able to contact the Korea Baduk Association about broadcasting rights for English casts of future top professional matches, so the amount of material for people learning the game should increase considerably.
Refinement of opening theory
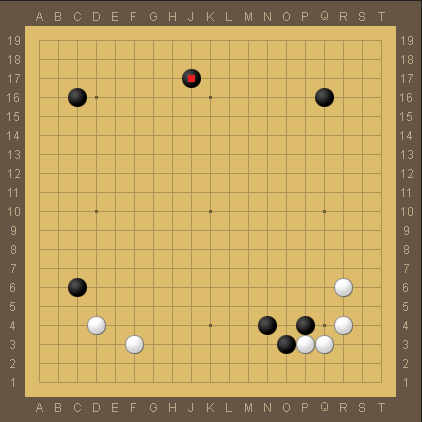
Here is the board after move 13 of game 2. This move by AlphaGo stuck out in my mind because AlphaGo decided to play away from the position at the lower right. Typically, once black adds the N4 stone, black is hesitant to play away because the group can still be attacked and playing N4 made it more difficult to sacrifice (because it's worth more points).
However, the opening has so many possibilities that it is difficult even for professionals to have definitive answers about whether a move is good or bad. Opening theory has radically changed twice in the past, and with AlphaGo's assistance it could change for a third time. I would not suggest that AlphaGo can find all the best moves in the opening, but it should be a useful tool for suggesting new variations that can be evaluated, or leading to existing variations to be reevaluated.
Finding mistakes in review
Professionals review their games all the time, and tracking AlphaGo's evaluation could be extremely helpful for them to not only find out where potential mistakes were, but also show alternative variations with potentially better results. As we saw in games 4 and 5, AlphaGo's moves are not perfect, but it should be a great starting point.
Where AlphaGo falls short
I believe that AlphaGo in its current state will be unhelpful for analyzing endgames. As we saw, while AlphaGo plays extremely well while close, it plays disastrously while behind. Additionally, when AlphaGo is ahead, it might play moves that lose points, as long as that point loss does not cause it to lose the game.
As a result, if you were to analyze a human endgame with AlphaGo, it will likely make poor recommendations for the trailing player, and additionally may make recommendations for the winning player that are fine for the current game, but do not generalize. So it might be possible to use AlphaGo to find optimal endgame by adjusting the rest of the territories so that the game is close, but doing so involves jumping through more hoops than would be ideal.
The future of AlphaGo
One aspect of AlphaGo is that it relies on human go knowledge in two places. First, the policy network is trained via supervised learning in order to predict human moves for a given board position. Second, the feature set is not just the positions of stones on the board, but also includes some particularly chosen properties of the stones, including special inputs for whether a stone can be captured in a ladder.
DeepMind has suggested that they want to try having AlphaGo learn the game from scratch, rather than starting with a human dataset. I believe this work will be very interesting, especially if they also abandon their human-selected features. Additionally, my understanding is that they tried reinforcement learning for both the policy network and the value network, but while the reinforcement learning on the value network improved AlphaGo, the reinforcement learning on the policy network actually made it perform worse, due to overly prioritizing the move it believes is best, rather than allowing the Monte Carlo Tree Search to evaluate a wider range of moves. So it will be interesting to see what techniques will be used in order to allow the policy network to learn well in an unsupervised environment.
Predictions
I'll close this blog post with some predictions about the future of go and go playing programs.
- Top professionals will be clearly stronger than today's AlphaGo within 5 years. I could even see this happening in a timespan as short as a single year.
- The weakness in reading semeai is inherent to Monte Carlo Tree Search, and will require new techniques in order to evaluate such positions properly.
- Professional play 10 years from now will still look similar to professional play from today, but more refined. In particular, the third/fourth line will still be the common territory/influence boundary.
- New techniques (as opposed to incremental improvements or better hardware) will be required for go programs to reach superhuman level 2.